removing barriers on the way of knowledge
---摘自sci-hub的首页
知识无国界,希望也不再用于套路
今天小编发现了一款可以OCR文本识别,同时自动翻译的科研神器,分分钟搞定PDF文本识别、sci论文翻译,用起来特别6(注意这个软件杀毒软件可能会报毒,介意的小伙伴请勿下载安装)
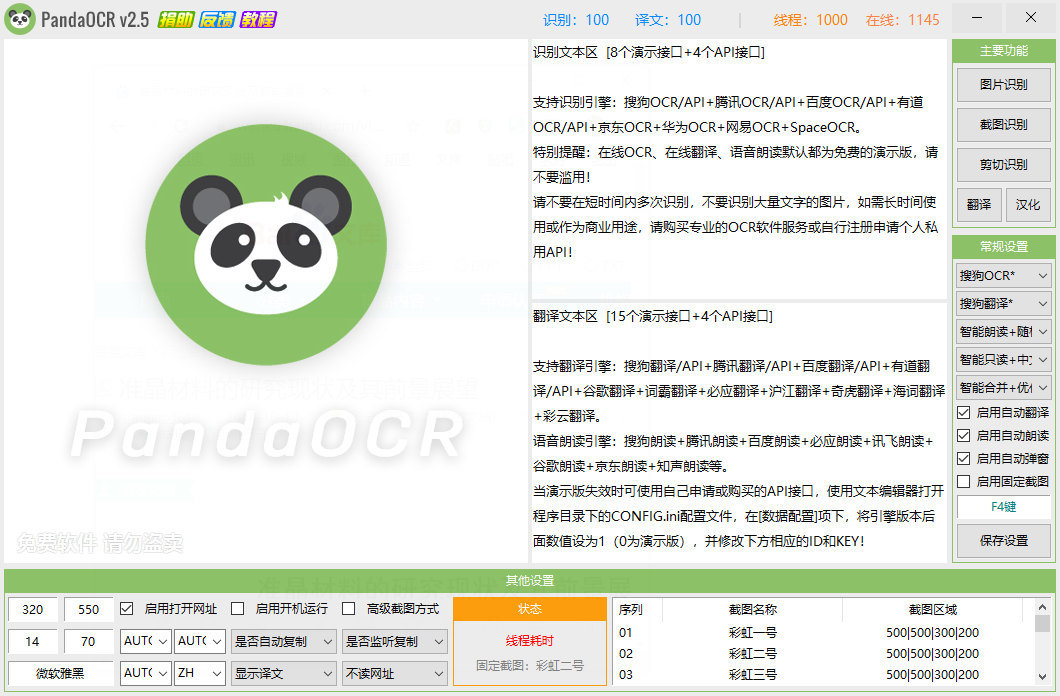
这就是这个神器的主页面
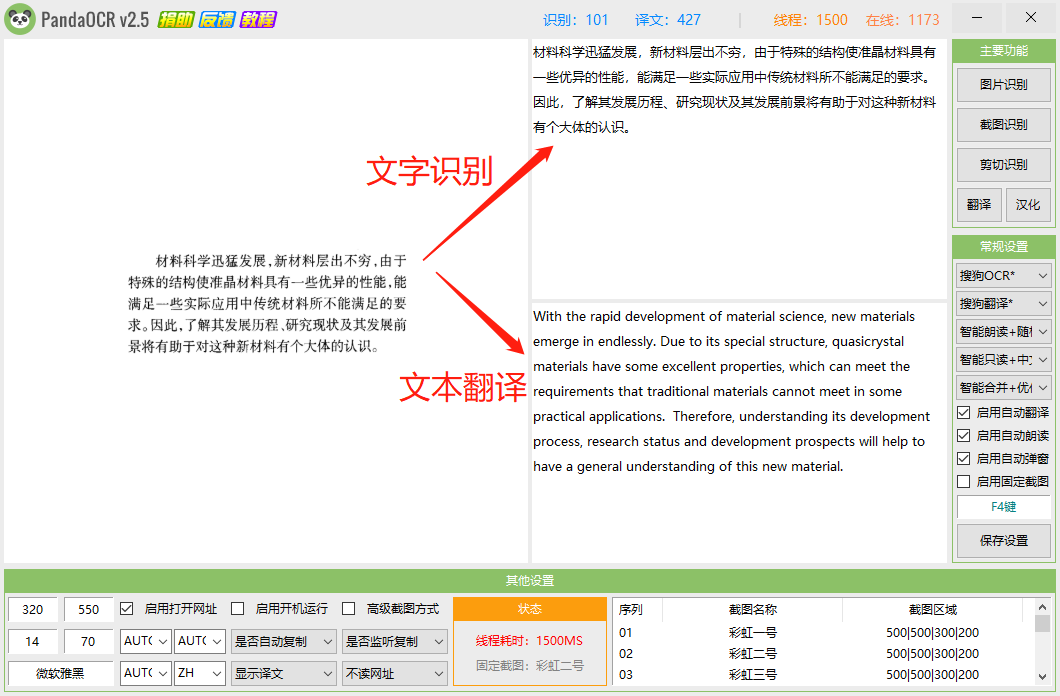
点击截图识别,可以截取图片并自动识别图片的文字为可编辑的文本,同时自动翻译
点击图片识别,可以选择已存在的图片进行识别和翻译
也可以在文本框里粘贴文本进行翻译
当然翻译英文文献也不在话下
更多技能可以点击左上角的教程来解锁

那么如何安装这个软件呢(注意这个软件杀毒软件可能会报毒,介意的请勿下载安装)
1. 解压压缩包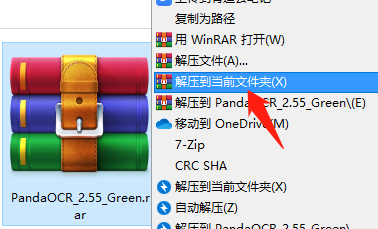

发送到桌面快捷方式
4. 软件界面如下
现在,这份资料无条件无套路分享给大家。小编在公众号设置了自动回复功能,在公众号后台回复关键词:OCR,即可一秒钟获得所有的资料网盘链接(不强求分享微信群和朋友圈,无需等待24小时或者48小时,我们充分尊重每一位关注的小伙伴,不玩那些套路,真正无条件分享资料)。

一个无套路的公众号,值得您的关注和分享